- Retrieves and validates session information from the repository.
- Performs pushdown optimization when the session is configured for push down optimization.
- Adds partitions to the session when the session is configured for dynamic partitioning.
- Forms partition groups when the session is configured to run on a grid.
- Expands the service process variables, session parameters, and mapping variables and parameters.
- Creates the session log.
- Validates source and target code pages.
- Verifies connection object permissions.
- Runs pre-session shell commands, stored procedures, and SQL.
- Sends a request to start worker DTM processes on other nodes when the session is configured to run on a grid.
- Creates and runs mapping, reader, writer, and transformation threads to extract, transform, and load data.
- Runs post-session stored procedures, SQL, and shell commands.
- Sends post-session email.
Data Transformation Manager (DTM) Process
Data Transformation Manager (DTM) Process: When the workflow reaches a session, the Integration Service process starts the DTM process.The DTM is the process associated with the session task. The DTM process performs the following tasks:
Function of load balancer in informatica-load balancer in informatica
The Load Balancer is a component of the Integration Service that dispatches tasks to achieve optimal performance and scalability. When you run a workflow, the Load Balancer dispatches the Session, Command, and predefined Event-Wait tasks within the workflow. The Load Balancer matches task requirements with resource availability to identify the best node to run a task. It dispatches the task to an Integration Service process running on the node. It may dispatch tasks to a single node or across nodes.
The Load Balancer dispatches tasks in the order it receives them. When the Load Balancer needs to dispatch more Session and Command tasks than the Integration Service can run, it places the tasks it cannot run in a queue. When nodes become available, the Load Balancer dispatches tasks from the queue in the order determined by the workflow service level.
The following concepts describe Load Balancer functionality:
- Dispatch process. The Load Balancer performs several steps to dispatch tasks.
- Resources. The Load Balancer can use PowerCenter resources to determine if it can dispatch a task to a node.
- Resource provision thresholds. The Load Balancer uses resource provision thresholds to determine whether it can start additional tasks on a node.
- Dispatch mode. The dispatch mode determines how the Load Balancer selects nodes for dispatch.
- Service levels. When multiple tasks are waiting in the dispatch queue, the Load Balancer uses service levels to determine the order in which to dispatch tasks from the queue.
Integration Service Process
The Integration Service starts an Integration Service process to run and monitor workflows. The Integration Service process accepts requests from the PowerCenter Client and from pmcmd. It performs the following tasks:
- ƒ Manages workflow scheduling.
- ƒ Locks and reads the workflow.
- ƒ Reads the parameter file.
- ƒ Creates the workflow log.
- ƒ Runs workflow tasks and evaluates the conditional links connecting tasks.
- ƒ Starts the DTM process or processes to run the session.
- ƒ Writes historical run information to the repository.
- ƒ Sends post-session email in the event of a DTM failure.
Managing Workflow Scheduling
The Integration Service process manages workflow scheduling in the following situations:
When you start the Integration Service. When you start the Integration Service, it queries the repository for a list of workflows configured to run on it.
When you save a workflow. When you save a workflow assigned to an Integration Service to the repository, the Integration Service process adds the workflow to or removes the workflow from the schedule queue.
Locking and Reading the Workflow
When the Integration Service process starts a workflow, it requests an execute lock on the workflow from the repository. The execute lock allows it to run the workflow and prevent you from starting the workflow again until it completes. If the workflow is already locked, the Integration Service process cannot start the workflow. A workflow may be locked if it is already running. The Integration Service process also reads the workflow from the repository at workflow run time. It reads all links and tasks in the workflow except sessions and worklet instances. The DTM retrieves the session and mapping from the repository at session run time. It reads the worklets from the repository when the worklet starts.
Informatica integration service configuration-Informatica integration service architecture
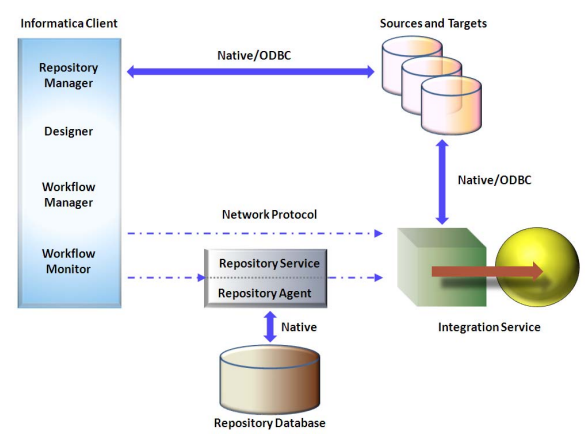
The Integration Service moves data from sources to targets based on workflow and mapping metadata stored in a repository. When a workflow starts, the Integration Service retrieves mapping, workflow, and session metadata from the repository. It extracts data from the mapping sources and stores the data in memory while it applies the transformation rules configured in the mapping. The Integration Service loads the transformed data into one or more targets. Figure below shows the processing path between the Integration Service, repository, source, and target:

To move data from sources to targets, the Integration Service uses the following components:
- Integration Service process. The Integration Service starts one or more Integration Service processes to run and monitor workflows. When you run a workflow, the Integration Service process starts and locks the workflow, runs the workflow tasks, and starts the process to run sessions.
- Load Balancer. The Integration Service uses the Load Balancer to dispatch tasks. The Load Balancer dispatches tasks to achieve optimal performance. It may dispatch tasks to a single node or across the nodes in a grid.
- Data Transformation Manager (DTM) process. The Integration Service starts a DTM process to run each Session and Command task within a workflow. The DTM process performs session validations, creates threads to initialize the session, read, write, and transform data, and handles pre- and post- session operations.
The Integration Service can achieve high performance using symmetric multi-processing systems. It can start and run multiple tasks concurrently. It can also concurrently process partitions within a single session. When you create multiple partitions within a session, the Integration Service creates multiple database connections to a single source and extracts a separate range of data for each connection. It also transforms and loads the data in parallel. Integration Service can be created on a Windows or UNIX server machine. The Integration Service could be configured using the Administration Console or the pmcmd command line program.
Informatica Services Connectivity
The Integration Service process connects to the source or target database using ODBC or native drivers. It connects to the Repository Service to retrieve workflow and mapping metadata from the repository database. The Informatica Client tools like the Workflow Manager communicates with the Integration Service and the Repository Service process over a TCP/IP connection.
Informatica server components-Informatica Client components
When a workflow starts, the Informatica Server retrieves mapping, workflow, and session metadata from the repository to extract data from the source, transform it, and load it into the target. It also runs the tasks in the workflow. The Informatica Server uses Load Manager and Data Transformation Manager (DTM) processes to run the workflow.
Server Components
Integration Service. Integration Service manages the scheduling and execution of workflows. It reads mapping and session information from the repository, extracts data from the mapping sources and stores the data in memory while it applies the transformation rules that you configure in the mapping. It loads the transformed data into the mapping targets. You can achieve high performance using symmetric multi-processing systems, start and run multiple workflows concurrently and concurrently process partitions
within a single session.
 |
| Informatica Server-Client Architecture |
Repository Service. Repository Service manages the metadata in the repository database and repository connection requests from client applications. For each repository database registered with the Repository Server, it configures and manages a Repository Agent process. It monitors the status of running Repository Agents, and sends repository object notification messages to client applications. The Repository Agent is a separate, multi-threaded process that retrieves, inserts, and updates metadata in the repository database tables. The Repository Agent ensures the consistency of metadata in the repository by employing object locking.
Web Services Hub. The Web Services Hub is a gateway that exposes PowerCenter functionality to external clients. It receives requests from web service clients and passes them to the Integration Service or Repository Service. The Integration Service or Repository Service processes the requests and sends a response to the web service client through the Web Services Hub.
SAP BW Services. The SAP BW Service listens for RFC requests from SAP BW and initiates workflows to extract from or load to SAP BW. The SAP BW Service is not highly available. You can configure it to run on one node
Client Components
Repository Server Administration Console. Repository Server Administration Console is used to add, edit, and remove repository configurations. It is also used to export and import repository configurations, create, promote, copy, delete, backup and restore repositories.
Repository Manager. Repository Manager is used for administering the repository, perform folder functions like create, edit and delete folders. It is also used to copy a folder within a repository or to other repository, compare folders, and implement repository security. Also, it allows us to create, edit and delete repository users and user groups, assign and revoke repository privileges and folder permissions, view locks and un-lock objects. You can import and export repository connection information in the registry, analyze source/target, mapping dependencies and view the properties of repository objects.
Designer. Designer provides five tools with which you can create mappings. Source Analyzer is used to import or create source definitions for flat file, ERP, and relational sources. Warehouse Designer is used to import or create target definitions. Transformation developer is used to create reusable transformations. Mapplet designer is used to create mapplets. Mapping designer is used to create mappings.
Workflow Manager. Workflow Manager is used to create Workflow which is a set of instructions to execute mappings. Generally, a workflow contains a Session and any other task you may want to perform when you execute a session Tasks can include a Session, Email, or Scheduling information. You connect each task with Links in the workflow You can also create a worklet in the Workflow Manager. A Worklet is an object that groups a set of tasks.
Workflow Monitor. Workflow Monitor is used to monitor workflows and tasks. You can view details about a workflow or task in either Gantt Chart view or Task view. You can run, stop, abort, and resume workflows. Displays workflows that have run at least once. Continuously receives information from the Integration Service and Rep
Informatica Overview- Key Benefits- Key Features
Informatica provides a single enterprise data integration platform to help organizations access, transform, and integrate data from a large variety of systems and deliver that information to other transactional systems, real-time business processes, and users.
Informatica supports the activities of Business Integration Competency Center (ICC) and other integration experts by serving as the foundation for data warehousing, data migration, consolidation, “single-view,” metadata management and synchronization.
Informatica: Key Benefits
With Informatica you can
- Integrate data to provide business users holistic access to enterprise data - data is comprehensive, accurate, and timely.
- Scale and respond to business needs for information - deliver data in a secure, scalable environment that provides immediate data access to all disparate sources.
- Simplify design, collaboration, and re-use to reduce developers' time to results - unique metadata management helps boost efficiency to meet changing market demands.
Informatica: Key Features
- Enterprise-level data integration. Informatica ensures accuracy of data through a single environment for transforming, profiling, integrating, cleansing, and reconciling data and managing metadata.
- Security. Informatica ensures security through complete user authentication, granular privacy management, and secure transport of your data.
- Visual Interface. Informatica is an easy to use tool with a simple visual interface for designing the integration.
- Developer productivity. Informatica simplifies design processes by making it easy to search and profile data, reuse objects across teams and projects, and leverage metadata.
- Compatibility. Informatica can communicate with a wide range of data sources and move huge volume of data between them effectively.
Popular ETL Tools-Famous ETL Tools in Market
ETL tools – see the table below – are widely used for extracting, cleaning, transforming and loading data from different systems, often into a data warehouse. The following ETL tools were thoroughly examined on 90 criteria.
Listed below are the products that are included in our ETL tool comparison. The numbers have no significance in terms of how highly the products scored in the evaluation. Click on the name of the ETL tool for more information and discover what the best ETL tool is for your organization.
| No. | List of ETL Tools | Version | ETL Vendors |
| 1. | Oracle Warehouse Builder (OWB) | 11gR1 | Oracle |
| 2. | Data Services | XI 4.0 | SAP Business Objects |
| 3. | IBM Infosphere Information Server | 9.1 | IBM |
| 4. | SAS Data Integration Studio | 9.4M1 | SAS Institute |
| 5. | PowerCenter Informatica | 9.5 | Informatica |
| 6. | Elixir Repertoire | 7.2.2 | Elixir |
| 7. | Data Migrator | 7.7 | Information Builders |
| 8. | SQL Server Integration Services | 10 | Microsoft |
| 9. | Talend Studio for Data Integration | 5.2 | Talend |
| 10. | DataFlow Manager | 6.5 | Pitney Bowes Business Insight |
| 11. | Pervasive Data Integrator | 10.0 | Actian (Pervasive Software) |
| 12. | Open Text Integration Center | 7.1 | Open Text |
| 13. | Oracle Data Integrator (ODI) | 11.1.1.5 | Oracle |
| 14. | Data Manager/Decision Stream | 8.2 | IBM (Cognos) |
| 15. | Clover ETL | 3.4.1 | Javlin |
| 16. | Centerprise | 6.0 | Astera |
| 17. | DB2 Infosphere Warehouse Edition | 9.1 | IBM |
| 18. | Pentaho Data Integration | 4.1 | Pentaho |
| 19 | Adeptia Integration Suite | 5.1 | Adeptia |
| 20. | DMExpress | 5.5 | Syncsort |
| 21. | Expressor Data Integration | 3.7 | QlikTech |
| 22. | Relational Junction ETL Manager | 5.3 | Sesame Software |
ETL Process flow
During Extraction, the desired data is identified and extracted from many different sources, including database systems and applications. Very often, it is not possible to identify the specific subset of interest; therefore more data than necessary has to be extracted, so the identification of the relevant data will be done at a later point in time. After extracting data, it has to be physically transported to an intermediate system for further processing.
Depending on the chosen way of transportation, some transformations can be done during this process, too. For example, a SQL statement which directly accesses a remote target through a gateway can concatenate two columns as part of the SELECT statement. Based on the requirements, some transformations may take place during the Transformation and Execution Phase. Through Informatica mappings, the necessary changes and updates of the data are made using transformations.

Then in the Load phase the data is loaded in the target. After all the transformations, it has to be physically transported to the target system for loading the data into the Target.
ETL Loading process
In loading stage, some data are loaded to the target directly without applying any transformation logic and some data are loaded to the target after applying the logic or business rules. The load phase loads the data into the end target, usually the Data Warehouse (DW). Depending on the requirements of the organization, this process varies widely. Some data warehouses may overwrite existing information with cumulative, updated data every week, while other DW (or even other parts of the same DW) may add new data in a historized form, for example, hourly. The timing and scope to replace or append are strategic design choices dependent on the time available and the business needs. More complex systems maintain a history and audit trail of all changes to the data loaded in the DW

As the load phase interacts with a database, the constraints defined in the database schema, as well as in triggers activated upon data load apply (for example, uniqueness, referential integrity, mandatory fields), which also contribute to the overall data quality performance of the ETL process.
ETL Transformation process
ETL Transformation process :: The transform stage applies to a series of rules or functions to the extracted data from the source to derive the data for loading into the end target. Some data sources will require very little or even no manipulation of data. In other cases, one or more of the following transformations types to meet the business and technical needs of the end target may be required:
- ƒ Selecting only certain columns to load (or selecting null columns not to load)
- ƒ Translating coded values and automated data cleansing
- ƒ Encoding free-form values
- ƒ Deriving a new calculated value
- ƒ Filtering
- ƒ Sorting
- ƒ Joining data from multiple sources
- ƒ Aggregation
- ƒ Generating surrogate-key values
- ƒ Transposing or pivoting columns
- ƒ Splitting a column into multiple columns
Applying any form of simple or complex data validation. If validation fails, it may result in a full, partial or no rejection of the data, and thus none, some or all the data is handed over to the next step, depending on the rule design and exception handling. Many of the above transformations may result in exceptions, for example, when a code translation parses an unknown code in the extracted data.

In Source, the data available is First name and Last name. To get the full name, the transformation logic is applied by concatenating both the first and last name. The place where these transformations take place is called the Staging Area.
In Source, the data available is First name and Last name. To get the full name, the transformation logic is applied by concatenating both the first and last name. The place where these transformations take place is called the Staging Area.
ETL Data Extraction process
The first part of an ETL process involves extracting the data from the source systems. Most data warehousing projects consolidate data from different source systems. Each separate system may also use a different data organization / format. Common data source formats are relational databases and flat files, but may include non-relational database structures such as Information Management System (IMS) or other data structures such as Virtual Storage Access Method (VSAM) or Indexed Sequential Access Method (ISAM), or even fetching from outside sources such as web spidering or screen-scraping. Extraction converts the data into a format for transformation processing.An intrinsic part of the extraction involves the parsing of extracted data, resulting in a check if the data meets an expected pattern or structure. If not, the data may be rejected entirely.

ETL Terms
Source System
Source System is a database, application, file, or other storage facility from which the data in a data warehouse is derived. Some of them are Flat files, Oracle Tables, Microsoft SQL server tables, COBOL Sources, XML files.
Mapping
Mapping is the definition of the relationship and data flow between source and target objects. It is a pictorial representation about the flow of data from source to target.
Metadata
Metadata describes data and other structures, such as objects, business rules, and processes. For example, the schema design of a data warehouse is typically stored in a repository as metadata, which is used to generate scripts used to build and populate the data warehouse. Metadata contains all the information about the source tables, target tables, the transformations, so that it will be useful and easy to perform transformations during the ETL process. A repository contains metadata.
Staging Area
Staging area is place where you hold temporary tables on data warehouse server. Staging tables are connected to work area or fact tables. We basically need staging area to hold the data, and perform data cleansing and merging, before loading the data into warehouse. Informatica
Data Cleansing
It is the process of resolving inconsistencies and fixing the anomalies in source data, typically as part of the ETL process. The data cleansing technology improves data quality by validating, correctly naming and standardizing data. For example, a person's address may not be same in all source systems because of typos and postal code, city name may not match with address. These errors can be corrected by using data cleansing process and standardized data can be loaded in target systems (data warehouse).
Transformation
Transformation is the process of manipulating data. Any manipulation beyond copying is a transformation. Examples include cleansing, aggregating, and integrating data from multiple sources. A transformation is a repository object that generates, modifies, or passes data. Target System Target System is a database, application, file, or other storage facility to which the "transformed source data" is loaded in a data warehouse.
What is ETL ?
ETL stands for Extraction, Transformation and Loading. ETL is a process that involves the
following tasks:
- Extracting data from source operational or archive systems which are the primary source of data for the data warehouse
- Transforming the data - which may involve cleaning, filtering, validating and applying business rules
- Loading
Subscribe to:
Posts (Atom)